
1.Introduction
Les outils ETL ne sont classiquement pas à ranger dans la catégorie des outils SIG mais les services qu’ils rendent aux gestionnaires de données méritent à notre sens une mise en lumière ; les frontières entre Data et GeoData n’étant pas toujours franches dans le quotidien du géomaticien.
Chez Agaric IG, nous travaillons régulièrement avec l’ETL Apache HOP ; nous vous proposons logiquement de revenir rapidement sur les origines et les grandes fonctionnalités de cet ETL open source.
2.L’ETL : Quésako ?
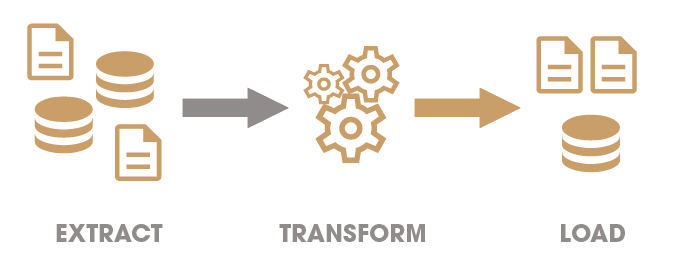
L’acronyme ETL signifie « Extract », « Transform » and « Load » et résume en quelques mots les fonctionnalités proposées par ce type d’outils.
- Extract : Lecture de données en provenance de sources et formats variés (fichiers tabulaires, base de données, logs applicatifs, services web, etc.)
- Transform : Processus visant à appliquer sur les données extraites des traitements spécifiques permettant de les « nettoyer » et de les « formater » pour les rendre « conformes » aux attentes de l’entreprise en terme de qualité et de structure dans un objectif de valorisation
- Load : Chargement des données transformées dans leur nouvel emplacement de destination
L’ETL est donc un outil de modélisation de processus. Selon l’outil employé, la modélisation est réalisée directement en codant le processus mais le plus souvent en exploitant un outil graphique de modélisation comme c’est le cas pour Apache Hop.
3.Origine d’Apache Hop et notions fondamentales
L’apparition d’Apache Hop dans le monde des ETL open source est relativement récente mais l’histoire de cet ETL remonte à la création, par Matt CASTERS, d’une première version d’un ETL open source dénommé « Kettle » (renommé ensuite Pentaho Data Intégration) intégré à la suite décisionnelle Pentaho puis, plus tard, à la suite Hitachi Vantara. Ces suites proposaient des versions Entreprise et Community.

Apache Hop est aujourd’hui un projet totalement open source de la fondation Apache mais se fonde sur la même logique de fonctionnement et une reprise du code source de ses prédécesseurs en s’articulant autour de 2 grandes notions : les « workflow » et les « pipeline »
Le « workflow » constitue un processus à point d’entrée unique qui permet d’enchaîner par des liens (hop) de manière successive ou parallèle des actions (pipeline ou autres actions) nécessaires à l’orchestration de la chaîne de traitement. Le « workflow » ne manipule donc pas de données en tant que telles mais constitue le processus chargé d’exécuter des processus « élémentaires » de traitements de données tels que les « pipeline »
Le « pipeline » constitue un processus de traitement de données tabulaires. Il est typiquement constitué par :
- L’extraction depuis une source de données (fichier CSV, table de base de données, flux JSON, etc)
- Une succession d’étapes de transformation de données (modification de la structure ou des valeurs du flux)
- Le stockage des données transformées au sein d’entrepôts ou de nouveaux fichiers de structures et de nature différentes des données d’origine.
Les « workflow » et « pipeline » modélisés pour une thématique spécifique peuvent être regroupés au sein d’un « project » auquel il est possible d’adjoindre des « metadata » (connexions aux bases de données, comportement à l’ exécution des processus, etc.) et d’associer des variables à exploiter dans différents « environment» (développement, test, production, etc.) : cela facilite le travail du concepteur de processus qui peut basculer rapidement d’un environnement à un autre en prenant en compte les spécificités propre à chacun (ex : environnement de développement sous MS Windows et de production sous Linux)
4.Fonctionnalités d’Apache Hop
4.1.Interface de modélisation
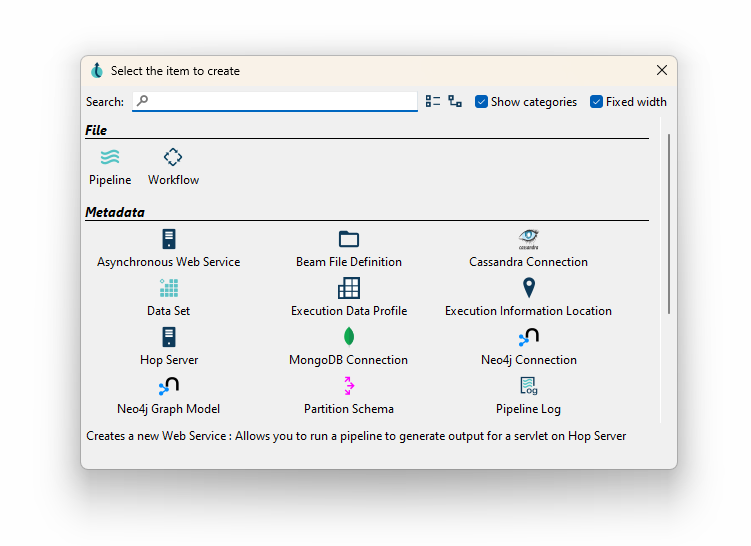
L’interface graphique d’Apache Hop (hop-gui) permet de construire graphiquement la totalité de la chaîne de traitement : création des projets, gestion des environnements, paramétrage des variables et des métadonnées, modélisation graphique des workflow et des pipeline
Cette interface est disponible en français mais nous recommandons de la conserver en anglais pour faciliter le lien avec la documentation disponible.
4.2.Fonctionnalités des « workflow »
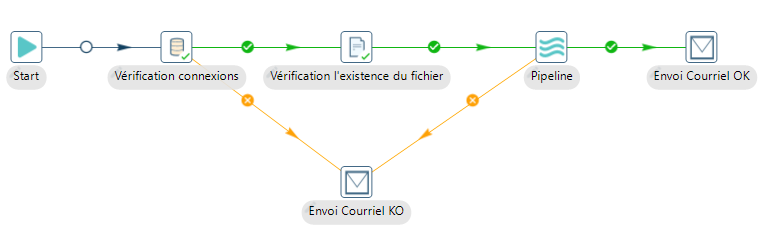
Dédiés à l’orchestration de processus « élémentaires » , les workflow proposent, en plus du chaînage de l’exécution de « Pipeline », des fonctionnalités variées telles que :
- la gestion de l’arborescence disque (copie de fichiers, création ou suppression de répertoires, etc.)
- la vérification de ressources (présence de fichiers à un emplacement spécifique, validité d’une connexion à une base de données, présence d’une table, conformité XML au regard d’un schéma, etc.),
- la notification (message dans les logs, envoie d’emails, etc.)
- le comportement à adopter en cas d’erreur à l’exécution d’un des maillons du workflow
4.3.Fonctionnalités des « pipeline »
Essence même de l’ETL Apache Hop, les « pipeline » traitent les données tabulaires d’origines variées, qu’elles proviennent de bases de données (Oracle, PostgreSQL, MS Sql Server, MySQL/MariaDb, Mongo, etc.) de fichiers (Tableurs, CSV, LDIF) ou de flux (Json,XML)
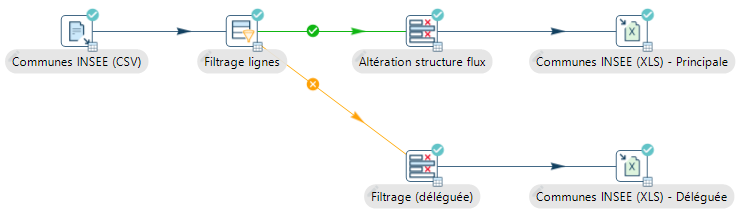
Les étapes de transformations proposées par Apache Hop permettent d’agir sur les données extraites pour permettre notamment :
- les jointures entre plusieurs sources (clef commune, produit cartésien, différences, etc.)
- la transformation de la structure ou des valeurs du flux (renommage/suppression de colonne, ajout d’une colonne calculée, remplacement de valeurs, agrégation de données, etc.)
- la validation des données (respect d’une expression régulière, type de données, présence d’un identifiant en base de données, etc.)
- le filtrage de données en appliquant des conditions permettant de scinder le flux principal en plusieurs « branches » pouvant ensuite être traitées spécifiquement.
- l’isolation des lignes en cas d’erreurs
La richesse fonctionnelle offerte peut être complétée par des instructions Javascript ou Java. Hop dispose également d’un mécanisme de plugins.
Les formats de fichiers et SGBD supportés en alimentation sont presque aussi variés que ceux proposés en extraction entrée et permettent de couvrir la grande majorité des besoins.
4.4.Fonctionnalités cartographiques
Apache HOP n’est pas un ETL disposant nativement de fonctionnalités lui permettant de manipuler l’information géographique. Une extension « GIS Plugins » est néanmoins disponible et permet à Hop de supporter au sein des pipeline le type « Geometry » des bases de données stockées sous Oracle, SQL Server, MariaDB et bien entendu PostGIS. La lecture et l’écriture des formats vectoriels communs (ESRI Shapefile, GeoJson, Geopackage) est également prise en charge. Cette extension n’a pas vocation à rivaliser avec les ETL Spatiaux spécialisés mais permet de répondre aux besoins simples de manipulation de l’information géographique. Sans cette extension Apache Hop nécessite l’exécution de commandes OGR pour réaliser les phases d’imports, d’exports et de transformations des jeux de données géographiques.

4.5.Exécution des processus
L’ETL Apache Hop est multi-plateformes et permet de répondre avec le même code applicatif à plusieurs cas d’usages :
- Usage « au quotidien » en mode « à la demande » : Apache Hop permet au gestionnaire de données de réaliser et de lancer des traitements d’intégration ou d’export de données directement depuis son poste de travail. Dans ce cas, l’exécution se déclenche directement par l’interface graphique.
- Usage en mode « tâche planifiée » : Déposés sur un serveur, les processus Apache Hop sont déclenchés à intervalles réguliers et permettent d’assurer les synchronisations de données entre les différentes entités du système d’information.
Contrairement à d’autres outils ETL, Apache HOP ne compile pas les processus pour permettre leur exécution par une autre machine : Apache Hop doit donc être déployé sur chaque machine en charge de l’exécution des traitements. Le déploiement des processus s’effectue par simple dépôts des fichiers du projet puis par paramétrage des tâches planifiées via les fonctionnalités proposées par le système d’exploitation.
5.Comment Agaric IG vous accompagne
Comme tout outil ETL, Apache Hop nécessite une phase d’apprentissage pour permettre un usage pertinent de l’outil.
Agaric IG accompagne les entreprises qui souhaitent utiliser Apache Hop en leur proposant :
- La réalisation de processus de traitement de données sur mesure en tenant compte de leurs besoins propres et leur environnement informatique
- Une formation d’une ou deux journées à l’utilisation d’Apache Hop
6.Quelques références clients
- Dijon Métropole – ProDIJ : Automatisation de la récupération des données d’indicateurs de qualité des sols à partir de saisie de laboratoire dans le cadre du volet « Sol Expert »
- Chambre régionale d’Agriculture de Bretagne – AgriVisioN’air : Récupération journalière des données de qualité de l’air pour mobilisation dans les processus de volatilisation de l’azote ammoniacal
- Association Air Breizh : Formation de 2 j à l’usage d’Apache Hop
- Ministère de l’agriculture (en sous traitance) : Formation de 2 j à l’usage d’Apache Hop