
Dans Apache Hop, la possibilité d’exécuter en boucles de traitements « élémentaires » avec passage (ou non) de paramètres constitue une fonctionnalité cruciale pour celui qui souhaite rationaliser à minima ses processus ETL.
Dans ce billet, nous revenons aujourd’hui sur les différentes possibilités proposées par Apache Hop pour traiter ce genre de besoins.
La méthode ancienne (à abandonner)
Les premières versions d’Apache Hop (antérieures à la version 2.5.0) n’héritaient que des fonctionnalités de gestion des boucles présentes dans Pentaho Data Integration. Cette méthode de modélisation des boucles est désormais à éviter mais il est bon d’en connaître le fonctionnement pour comprendre les processus en cas de reprise pour maintenance de processus « ancien »
Cette méthode impose la création d’un workflow qui exécute à minima :
- Un pipeline qui génère des lignes de données qui seront récupérées par le workflow parent qui pilote la boucle
- Un pipeline ou un workflow à exécuter pour chaque ligne récupérée
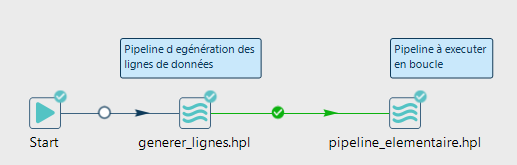
Workflow type mobilisant un pipeline qui génère des lignes et un pipeline à exécuter en boucle
Le pipeline qui génère les lignes de données (issues d’un fichier, d’une table, d’un service web, etc.) doit obligatoirement comporter une étape « Copy rows to result » qui se charge de transmettre au workflow parent les données qui pourront être transmises pour le paramétrage du processus (workflow ou pipleline) à exécuter en boucle.
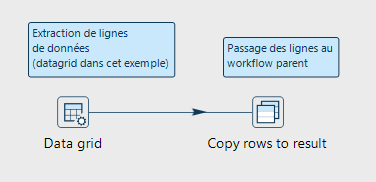
Génération de lignes et utilisation impérative de « Copy rows to result »
Le processus (pipeline ou le workflow) à exécuter en boucle est à appeler via une étape « workflow » ou « pipeline ». Le paramétrage de l’étape consiste alors :
- A renseigner le fichier pipeline ou workflow à exécuter
- A spécifier que le processus doit s’exécuter pour chaque ligne de résultat (les lignes issues du « Copy rows to result » du pipeline appelé en amont) via « Execute for every result row »
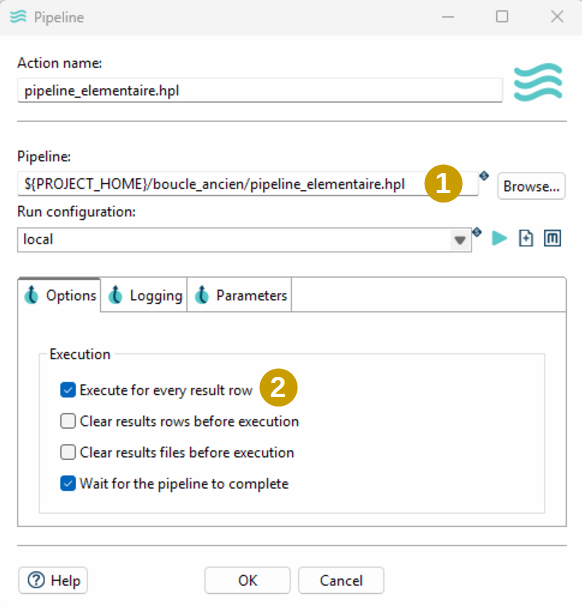
Paramétrage du pipeline à exécuter en boucle (indication qu’il faut boucler sur les lignes de résultats)
- A renseigner éventuellement l’onglet « Parameters » en associant paramètres attendus par le processus à exécuter en boucle et colonne de données de ligne de résultat
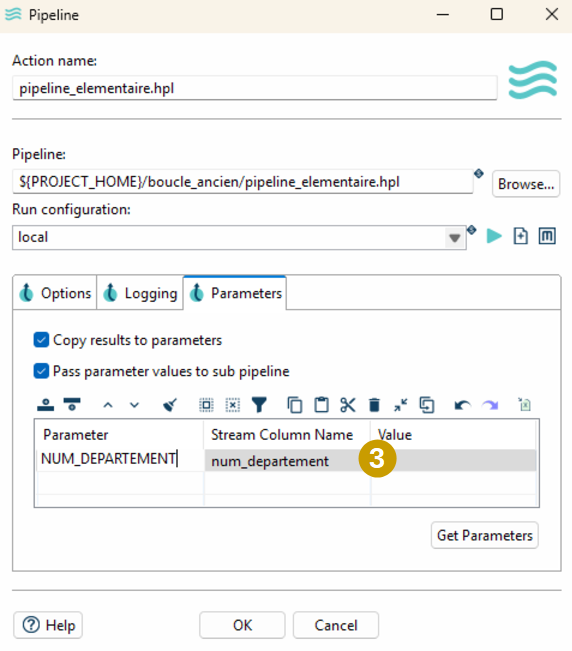
Paramétrage du pipeline à exécuter en boucle (passage de paramètres)
- Dans le cas d’un pipeline, à récupérer éventuellement les données de la ligne de résultat courante via une étape « Get rows from result »

Récupération dans le pipeline des informations de la ligne courante passée par le workflow parent
Astuce : Quand les lignes de données sur lesquelles boucler proviennent d’une source SQL, il est possible de s’affranchir d’un pipeline de « Génération de lignes » en valorisant certaines étapes comme « Evaluate rows number in table », « Wait for SQL », etc. qui proposent de retourner des lignes de résultats permettant de boucler (cocher « Add rows to results » pour ces étapes)
Les nouvelles méthodes
Boucler dans les pipeline
Depuis la version 2.5.0, Apache Hop propose des étapes (« Pipeline executor » et « Workflow executor ») permettant d’exécuter un pipeline ou un workflow directement dans un pipeline. Une de ces étapes placée sur un flux de données exécutera en boucle le processus appelé dès lors que plusieurs lignes sont présentes dans le flux du pipeline principal.

La création de boucles peut s’exécuter directement depuis un pipeline
Ces étapes permettent, comme les étapes « pipeline » ou « workflow » mobilisable dans les workflow de l’ancienne méthode de préciser le processus à exécuter ainsi que d’effectuer le passage de paramètres. Ces nouvelles étapes de pipeline permettent également de préciser :
- Les métriques liées au processus en cours
- Les lignes résultantes éventuelles dès lors qu’une étape « Copy rows to result est utilisée » dans le pipeline appelé ou «Add rows to result » pour les étapes de workflow qui proposent ce paramètre
- Les nom des fichiers éventuellement générés dès lors que l’on précise que le nom de fichier doit être ajouté au résultat (option disponible pour certaines étapes de sortie uniquement)
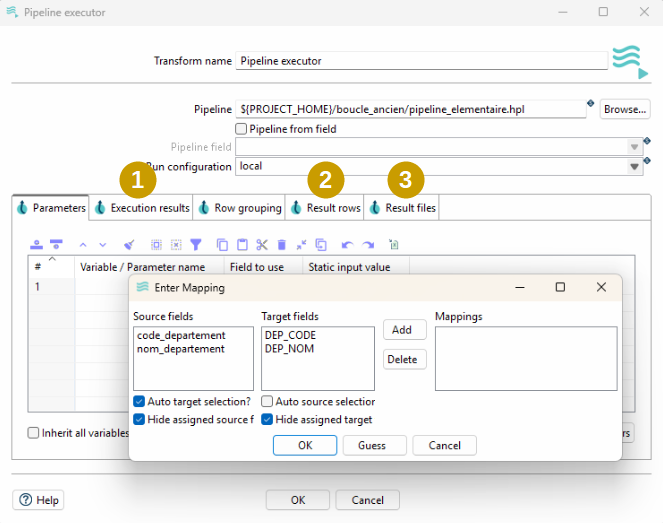
Astuce : La possibilité de retourner facilement des lignes de résultat au pipeline parent permet par exemple d’agréger en un seul flux principal des données provenant de plusieurs sources dès lors qu’elles disposent d’une structure identique (cf exemple ci-dessous avec les plugin GIS qui ne proposent pas la possibilité d’agréger les lignes de plusieurs fichiers directement dans l’étape de lecture)
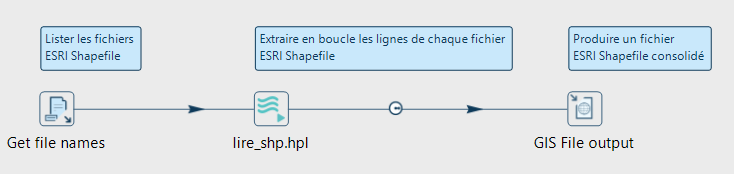
Pïpeline principal enchaînant les étapes de listage des fichiers SHP, d’extraction des données de chaque fichier et de consolidation des lignes dans un fichier unique.
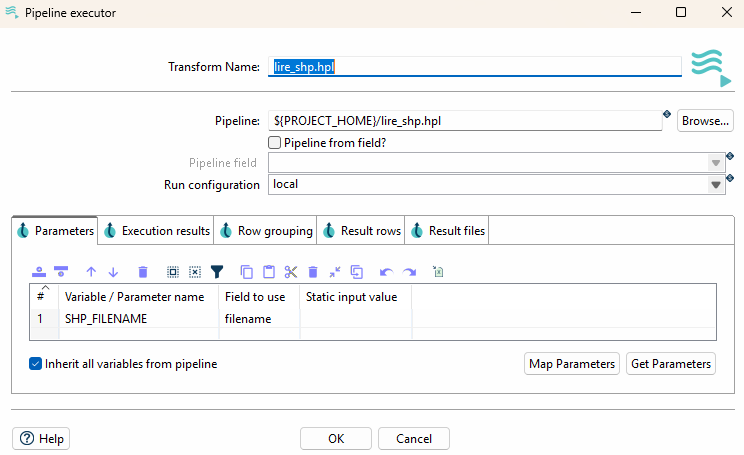
Passage du nom de fichier SHP à traiter en paramètre du « Pipeline executor »
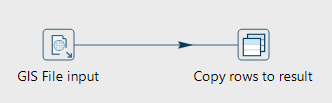
Pipeline élémentaire d’extraction des lignes du fichier SHP courant
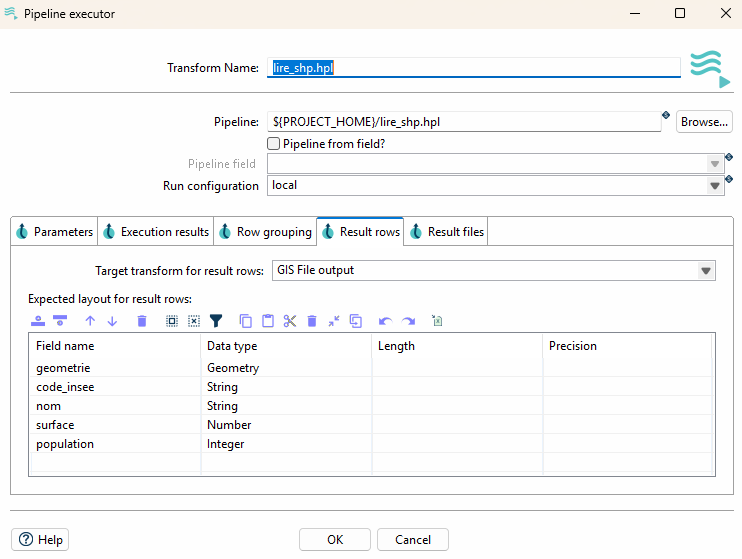
Paramétrage de la structure de ligne attendue en sortie d’exécution et choix de l’étape de sortie des lignes
Boucler dans les workflow
Apache Hop offre désormais la possibilité de réaliser des boucles dans les Workfow via les étapes « Repeat » et « End repeat ».
L’étape « Repeat » est similaire aux « executor » proposés dans les pipeline dans le sens où elle permet de préciser le pipeline ou le workflow a exécuter en boucle et qu’elle propose le passage de paramètres. Le workflow n’étant pas générateur de lignes, la boucle est exécutée indéfiniment sauf à préciser une condition d’arrêt, cette dernière pouvant être une étape « End Repeat » mobilisée dans le workflow appelée en boucle ou dès lors qu’une variable contient une valeur spécifique.
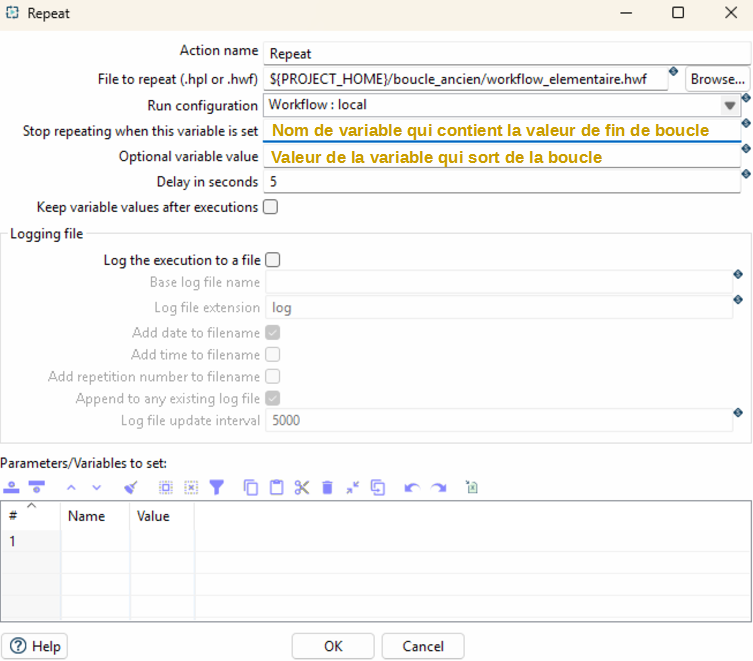
Paramétrage du « Workflow executor »
Astuce : Pour rappel, si l’objectif est de rejouer indéfiniment un processus à intervalle régulier vous disposez des alternatives suivantes :
- L’étape START qui propose de planifier le processus
- Planification avec Cron sous Linux ou le Planificateur de tâches sous Windows
- Les solutions logicielles dédiées à la planification (lien vers le billet DAGU)
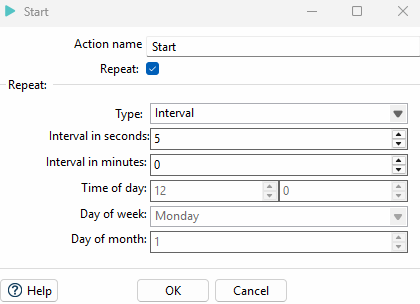
L’étape START d’un Workflow permet également d’executer des processus à intervalles réguliers