
Contrôler les données en amont pour limiter les risques d’erreurs liés aux données dans vos pipelines
Les équipes d’Agaric IG vous proposent sur le blog un tips, une astuce, une bonne pratique, qui pourra, peut être, vous simplifier le quotidien 😉 Pour ce troisième tips, on vous parle de la brique « Validation de données » (Data validator car non traduite à ce jour en français) de notre ETL préféré… Apache HOP.
Absente des premières versions d’Apache Hop, cette brique historiquement présente dans Pentaho Data Integration a fait son apparition dans Hop depuis la version 2.7.0.
Elle est mobilisable au sein d’un pipeline et permet notamment de contrôler les données en amont d’étapes susceptibles de provoquer des erreurs afin d’isoler les lignes du flux qui ne respecteraient pas les conditions de validité renseignées par l’utilisateur.
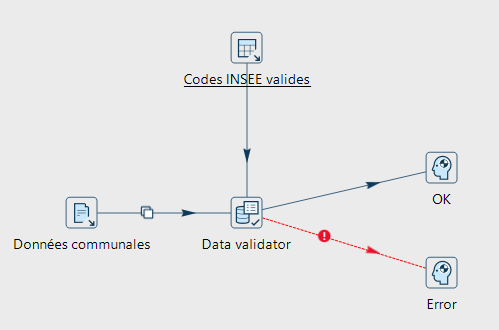
Usage type de la transformation « Data Validator » dans un pipeline
La validation des données s’effectue en ajoutant dans la transformation des règles de validation de données, une règle étant définie pour un champs du flux à contrôler.
Les informations a renseigner pour chaque règle se décomposent en 3 groupes :
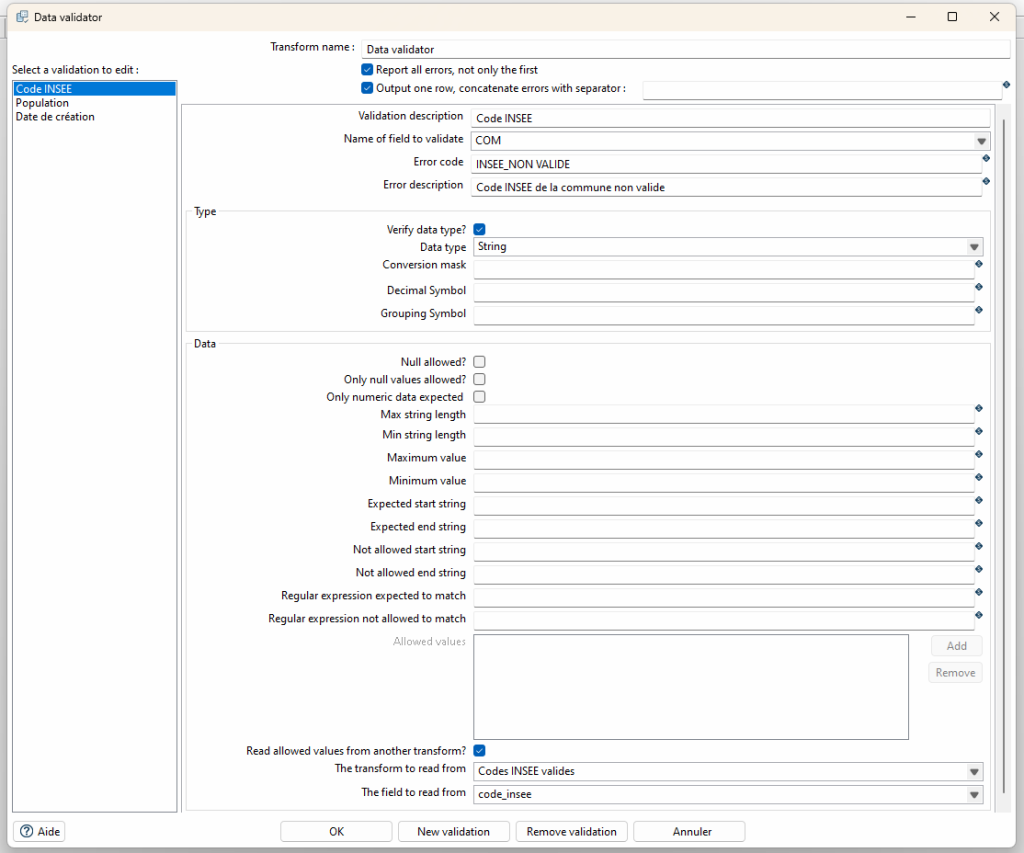
- Les informations de base telles que le nom de la règle, le champ du flux concerné ainsi que les code et description de l’erreur a retourner dans le cas où la règle n’est pas respectée
- Les conditions de validation de la structure du champ (type de donnée, séparateur de décimal, etc.)
- Les conditions de validation des valeurs contenues dans le flux pour le champ contrôlé. Des conditions standards sont proposées (non null, valeurs min ou max, chaîne de texte qui commence ou se termine par… Etc.) mais il est également possible de définir ses propres conditions en renseignant une expression régulière. L’étape permet également de s’assurer que les valeurs d’un champ font partie d’une liste de valeurs autorisées, ces dernières pouvant être renseignées en « dur » ou issues d’un autre flux présent dans le pipeline (ex : liste de code INSEE valides extraits d’une table des communes)
Cette étape de validation de données présente un réel intérêt puisqu’elle permet de limiter les risques d’erreurs d’un pipeline (pdate incorrecte, contrainte de clé étrangère en base de données qui ne sera pas respectée, etc.), en intervenant en amont. Néanmoins, compte tenu du temps nécessaire à son paramétrage, son usage est peut-être à réserver à des cas processus spécifiques comme la génération automatisée de rapports d’erreurs pour un utilisateur qui aurait déposé un jeu de données sur un espace dédié en vue d’une intégration automatisée.